
Introduction
Monitoring as code is emerging as a vital and sophisticated part of the cloud operations management mix. This goes beyond the automated installation of monitoring agents and plugins. At its best, monitoring as code significantly improves observability as well as automating diagnosis, alerts and incident management. It can also bring automation to the remediation of performance issues.
Datadog plays a central role in our cloud-managed services work. It enables us to differentiate between real problems and background noise, then mitigate potentially serious issues before they escalate.
Increasingly, we’re taking this to the next level using Terraform to manage Datadog resources on an ‘as code’ basis. As part of this, we develop monitoring as code templates that can be adapted according to customer need.
So, what are the benefits of working in this way?
Templated ‘as code’ Integrations Boost Efficiency and Effectiveness of Cloud Monitoring
Writing our own Datadog integrations using Terraform allows us to tailor data monitoring, management and retrieval more precisely. By templating these integrations, we can onboard new managed services customers quickly, enhancing their operational maturity. This means customers benefit from sophisticated, automated monitoring even if they’re at an early stage of cloud adoption. Effective monitoring underpins effective performance, stability and security, so it all adds up to a better overall cloud experience.
Read on to see some of the code we use to manage resource deployment within our customers’ Datadog accounts.
Re-usable Customer Templates
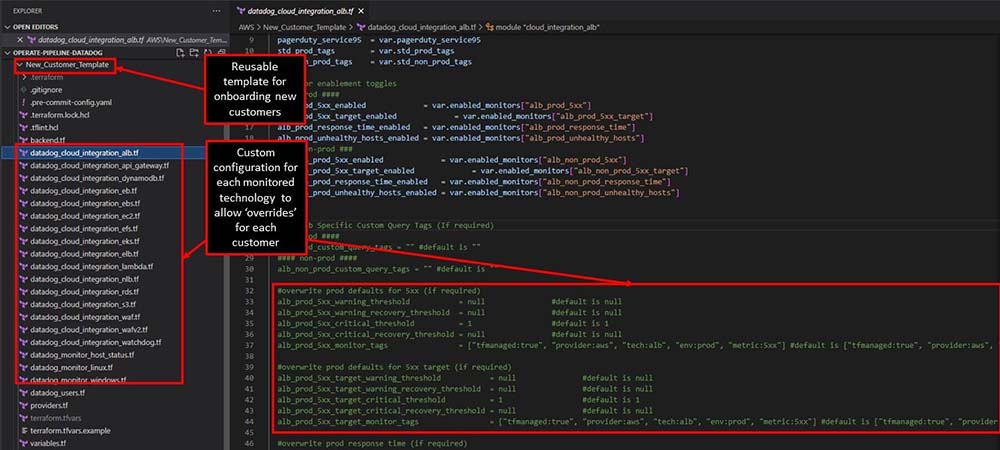
The below screengrab shows how we adapt templated Datadog integrations using Terraform during customer onboarding.
Configurations are customised according to each monitored technology, from load balancers to cloud databases to container orchestration. This structure means we can easily allow overrides in line with different cloud environments and the requirements of individual customers. Naturally, all templates adhere to ISO 27001 controls for information security management, and we have audit trails for transparency and traceability.
Customer Variables
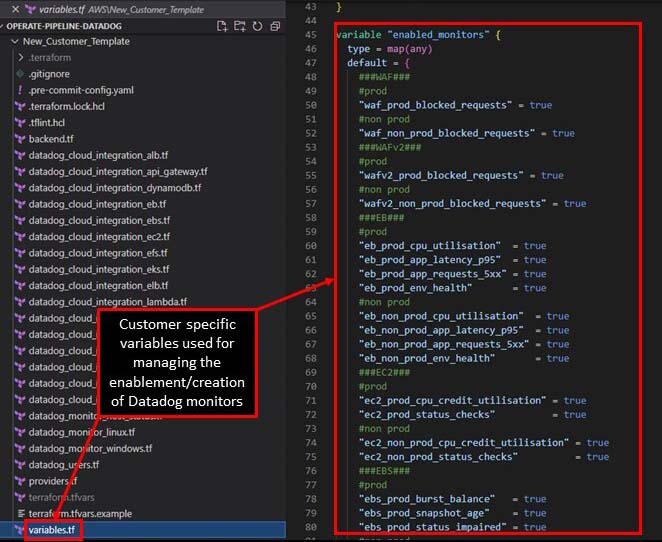
Introducing ‘variables’ to the template enables it to be adapted to specific customer needs.
We might use this to leverage Datadog’s composite alerts tool, where alerts are triggered by a combination of customer-specific symptoms that typically preclude a major issue such as an outage.
This approach avoids alert storms and reduces false positives. For instance, we might set the integration up to ignore an alert that we’d usually respond to, depending on whether it is triggered within a similar timeframe to a separate but related event. Typical events that this could apply to include a spike in URL endpoint latency, failover to a maintenance page due to health check failure or higher than normal resource consumption.
Any of these situations might arise at the same time as a pipeline notification for a new release being deployed to the monitored environment. Muting all the monitors would be like taking a sledgehammer to crack a nut; but unnecessary escalation wastes engineering time. Instead, we can factor in additional conditions – such as changing thresholds or ignoring specific events – when evaluating the metrics to determine whether intervention is necessary.
In the below screengrab, we’ve created various alerts across production and non-production environments. These provide valuable real-time insights of the cloud estate, enabling engineering workloads to be optimised to deliver continual improvement.
Re-usable modules
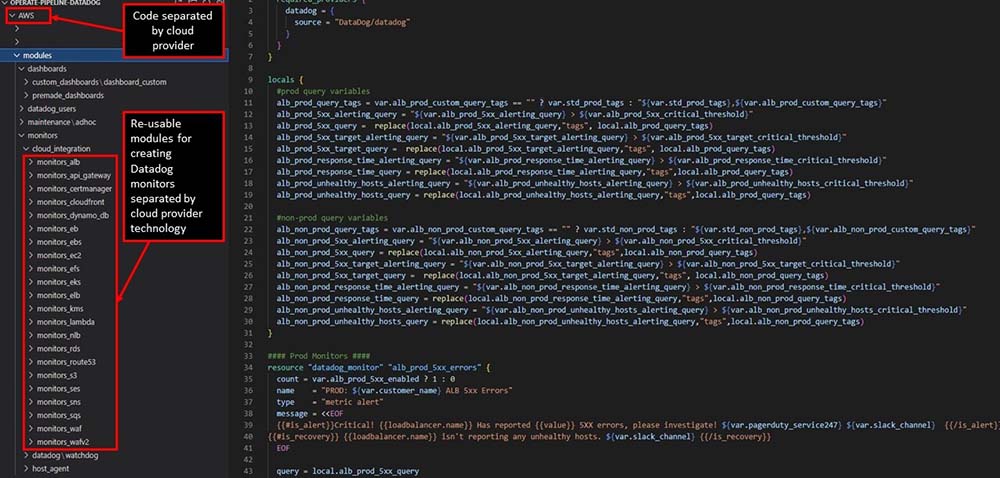
Our templates are segmented into Terraform modules which relate to the technologies of different cloud providers. So, in the below example, you can see modules for monitoring various AWS technologies such as Amazon API Gateway, the CloudFront content delivery network and the serverless compute service AWS Lambda.
We create independent profiles for each customer, incorporating whichever modules are relevant. The modules are nested, so if Datadog changes the functionality of its service for a given technology, we amend the code in the central template to update all customer profiles. Another advantage of modularising the codebase in this way is that it allows for robust change controls. We can rollback changes quickly if needed, as well as using a peer review process to sanity check and approve changes before deployment to production.
Continuous evaluation and evolution
Effective monitoring is the cornerstone of cloud operations best practice, and Datadog is an excellent tool for monitoring complex infrastructures. Combining this with Terraform raises the bar even further, advancing operational maturity. All of this plays a central role in the ongoing improvement of cloud infrastructures and the avoidance of unplanned downtime.
It’s important to note that Datadog itself is evolving at pace. New features, add-ons and updates are being released all the time. To keep on top of these changes we run an ongoing Datadog Hackathon where our engineers explore new releases. We have a rolling backlog of tickets to trial and test new updates. Learnings are added to an InnerSource repository along with information on how to get the most from each new release and scenarios where it might add value. More on this to follow in a future post!

Mike is a Lead Consultant at Sourced with over 20 years experience in the IT industry. He has worked across a wide range of platforms and technologies and held numerous roles during his carrier including those of a Network/Systems Engineer, Solutions Architect, Professional Services Consultant and Cloud Operations/SRE. He strives to keep abreast of the latest offerings from the various Cloud Service Providers to ensure our clients are always using the right tools for the job.


